Redis 面试指南
在这里收集一些 Redis 常见面试题,也欢迎大家在下方评论区提交更多面试题目。
为什么要使用 Redis?使用 Redis 有哪些好处?
基于内存速度快、丰富的数据类型、多语言支持、多功能支持,参考 todo://
Redis 与 Memcache 区别?
数据持久化、数据类型、Value 大小、网络 I/O 模型、数据一致性,参考 todo://
为什么 Redis 只适合用于缓存而不能当作数据库来使用?
这个问题需要从性能、成本、灵活性、数据可靠性等多方面来权衡考虑:
- 性能上考虑,Redis 是一个基于内存的数据库,通常用来做计数器、Session 存储、缓存设计等从性能上来说还是很不错的。
- 从成本考虑,假设百万条数据,仅 1% 是热点数据其余都为冷数据,这种情况下全部一股脑的放在 Redis 里,显然是资源的浪费,从缓存设计角度来讲,所保存的也仅是热点数据。
- 灵活性考虑,Redis 的数据结构是挺丰富的,支持 String、HashTable、List、Set、Zset 还有最新衍生的 BitMaps、GEO 等,如果有很复杂的查询语句、关联查询等,是不是 SQL 可能会更合适些呢?
- 数据可靠性考虑,第一种方式 Redis + RDB 的方式,如果发生断电,自上次持久化至最近一次故障之间的这些数据还是会丢失的。第二种方式 Redis + AOF,AOF 有三种策略将数据持久化到磁盘,其中 everysec 是相对折中的一种方案,everysec 这种方案也会存在 1 秒钟丢失数据的可能,所以也要看这种情况当前的业务场景能否接受?
综合考虑还是要根据具体的业务场景来选择,Redis + MySQL/MongoDB 等都是不错的方案。
Redis 中的数据如何持久化?
Redis 提供了 RDB 和 AOF 两种方式来对数据进行持久化操作:
RDB: RDB 是将当前内存中的数据集快照写入磁盘。恢复时将快照文件直接读到内存里(保存的是二进制数据)。提供了两种机制 save 和 bgsave,save 会造成客户端阻塞,因此生产不建议使用,使用 bgsave Redis 会 fork 一个子进程来负责生成 RDB 文件,阻塞发生在 fork 子进程过程中,遵循 Copy-On-Write(写入时复制) 策略,使用 bgsave 的 fork 是一个重量级操作,避免频繁调用。另外 RDB 的形式在一定时间可能会造成数据丢失。
AOF: 以写日志的方式执行 redis 命令之后,将数据写入到 AOF 日志文件。注意,这里需要设置 fsync 策略,通常 fsync 设置为每秒一次就能获得比较高的性能,也是 Redis 官方所默认的。AOF 这种形式一直写入会使得日志文件越来越庞大,对于重放会很慢,所以还需要进行 AOF 重写,对日志瘦身。
Redis 中如何选择合适的持久化?
以下从多个角度进行比较说明:
- 重放优先级: 系统重启时优先重放 AOF 备份的数据,随后是 RDB,因为从数据备份的完整性考虑,AOF 相比 RDB 可靠性更高些
- 恢复速度快:RDB 采用二进制方式存储占用体积小,AOF 是以日志形式存储,体积相比 RDB 要大,相比较来看,RDB 的数据恢复速度要高于 AOF
- 数据安全性:RDB 采用快照的形式,在一定时间内会丢失数据,AOF 相对更安全些主要有三种策略,也要看怎么选择
如果我们定时按照天、小时等单位来备份数据,RDB 快照这种形式还是可以的,对于 RDB 的操作不建议频繁,因为 RDB bgsave fork 也是一个很重的操作。对于 RDB 的快照文件可以保存在 Redis 当前服务器之外的其它服务器之上(鸡蛋不要放到同一个篮子里)。
一般来说, 如果想达到足以媲美 PostgreSQL 的数据安全性,应该同时使用两种持久化功能。如果你非常关心你的数据,但仍然可以承受数分钟以内的数据丢失,那么你可以只使用 RDB 持久化。有很多用户都只使用 AOF 持久化,但并不推荐这种方式:因为定时生成 RDB 快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度要快,除此之外, 使用 RDB 还可以避免罕见的 AOF 程序 bug。
Redis 主从复制原理?实现?
所谓主从复制就是一个 Redis 主节点拥有多个从节点,由主节点的数据单向的复制到从节点,为主节点提供了数据副本,如果主节点发生故障,从节点可以升级为主节点,使服务不受影响。
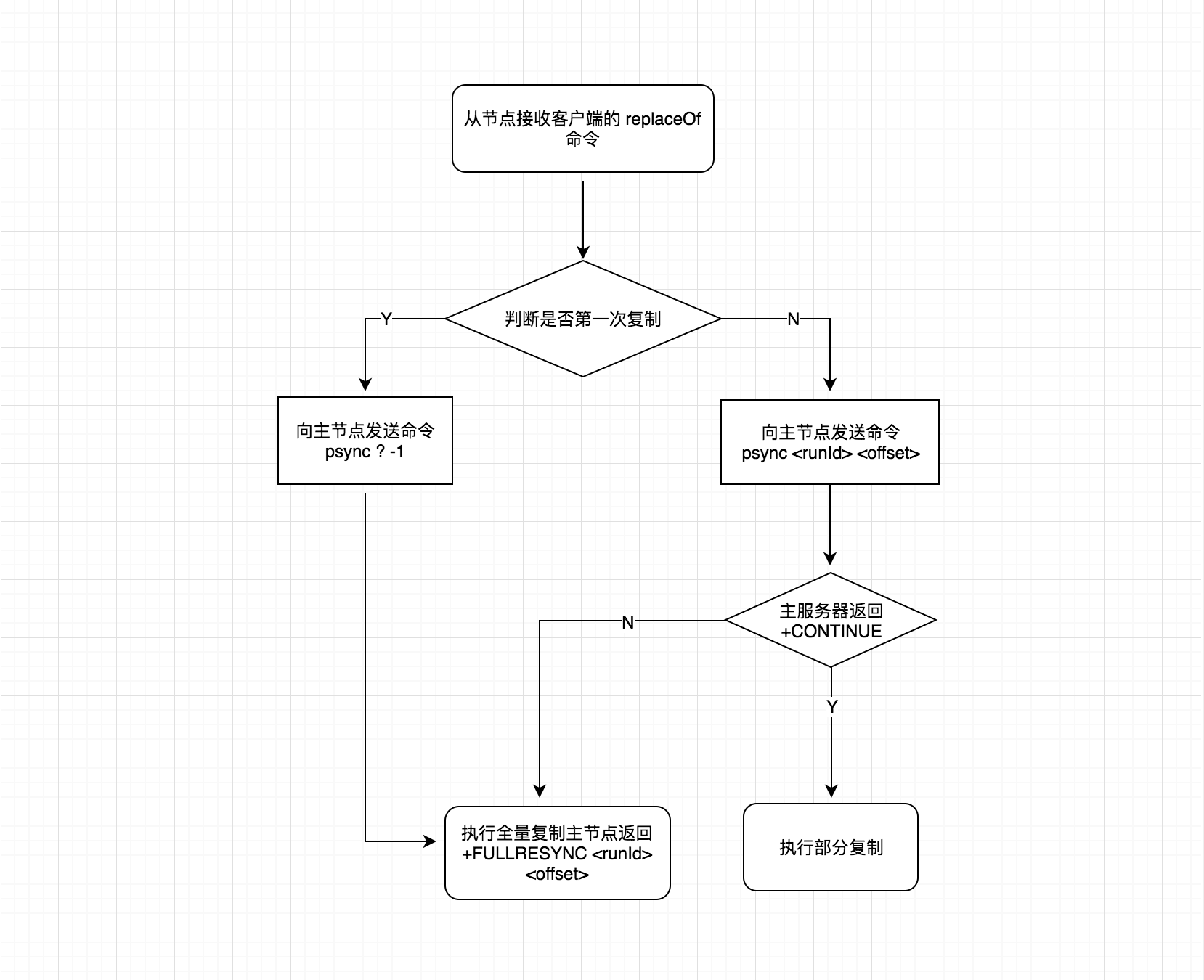
以上为主从复制实现,主要用到一个 psync 命令,详细可参考文章 todo://,包含了主从复制的实践
Redis Sentinel 解决了什么问题?
在 Redis 主从复制中,假设主节点发生故障之后,这个时间的数据将会丢失,因为从节点仅是主节点的一个备份节点,这个时候就需要故障转移,手动的去选一个 slave 做为主节点去工作,显然这样不是很好的。因此我们就需要一种机制自动的提升从节点,Redis 提供的 Sentinel 就可实现这一点,Redis Sentinel 是一个分布式系统,类似于 Consul 集群,一般由 3 ~ 5 个节点组成,使用 Raft 算法实现领导者选举因为故障转移工作只需要一个 Sentinel 节点来完成,如下图所示,我们客户端部分直接和 Sentinel 集群交互,关于 Redis 主从节点的状态维护交由 Sentinel 去管理。

上图展示了一个由 Sentinel 完成的节点故障自动转移。详细可参考文章 todo://,包含了 Redis Sentinel 的实践
什么情况下会导致整个 Redis Cluster 不可用?
Redis Cluster 的主从复制是为了保证在部分节点失败或无法通信时,整个集群仍可用,因此建议主节点要有至少 1 个从节点,假设集群中的一个主节点挂掉,集群会选举其从节点晋升为主节点,假设集群中的一个主节点失败了其从节点也没正常完成晋升,就会导致整个集群因为找不到槽而不可用。
Redis 哈希槽是什么?
Redis 没有使用一致性 HASH 算法而是引入哈希槽的概念,Redis 集群采用的虚拟哈希槽方式,共有 16384 个哈希槽,每个节点会划分一部分的槽位(16384 / 主节点数),当 Redis 集群客户端查询某个 Key 的信息时,首先会计算这个 Key 的 hash 值(CRC16 算法),通过对 16384 取余得到槽位,从而得到对应的信息。
HASH_SLOT = crc16(key) % 16384
每一个哈希槽中的 key 是如何存储的?
一个 Redis 集群会划分为 16384 个哈希槽,每个哈希槽可看成一个分区表,在插入数据时根据上面的 “槽位定位算法” 来决定你的 key 存储于哪个分区表。如果是单节点可以理解为所有的 key 都存在一个表里。
Redis Cluster 模式下如何选择数据库?
Redis 集群模式下不支持选择数据库,默认为 db0。另外,Redis 单实例默认为 16 个 db,从 db0 - db15。
Redis Cluster 模式会存在数据丢失吗?
Redis 并不能保证数据的强一致性. 这意味这在实际中集群在特定的条件下可能会丢失写操作.
异步复制
第一个原因是因为集群是用了异步复制. 写操作过程:
客户端向主节点B写入一条命令. 主节点B向客户端回复命令状态. 主节点将写操作复制给他得从节点 B1, B2 和 B3. 主节点对命令的复制工作发生在返回命令回复之后, 因为如果每次处理命令请求都需要等待复制操作完成的话, 那么主节点处理命令请求的速度将极大地降低 —— 我们必须在性能和一致性之间做出权衡。注意:Redis 集群可能会在将来提供同步写的方法。
网络分区
Redis 集群另外一种可能会丢失命令的情况是集群出现了网络分区, 并且一个客户端与至少包括一个主节点在内的少数实例被孤立。
举个例子 假设集群包含 A 、 B 、 C 、 A1 、 B1 、 C1 六个节点, 其中 A 、B 、C 为主节点, A1 、B1 、C1 为A,B,C的从节点, 还有一个客户端 Z1 假设集群中发生网络分区,那么集群可能会分为两方,大部分的一方包含节点 A 、C 、A1 、B1 和 C1 ,小部分的一方则包含节点 B 和客户端 Z1 .
Z1仍然能够向主节点B中写入, 如果网络分区发生时间较短,那么集群将会继续正常运作,如果分区的时间足够让大部分的一方将B1选举为新的master,那么Z1写入B中得数据便丢失了.
注意, 在网络分裂出现期间, 客户端 Z1 可以向主节点 B 发送写命令的最大时间是有限制的, 这一时间限制称为节点超时时间(node timeout), 是 Redis 集群的一个重要的配置选项
Redis 分布式锁如何实现?
Redis 字典和跳跃表原理?
Redis 过期键删除策略?
Redis 采用惰性删除、定时删除两种策略实现对过期 Key 进行内存回收。
惰性删除:当客户端操作带有设置过期键的 Key 时,如果 Key 已过期执行删除,返回空,另一种情况如果该 Key 一直没有访问就会造成无法及时删除,存在内存泄漏的风险,下面定时任务删除正是对 惰性删除 的补充。
定时删除:Redis 内部会维护一个定时任务检查、删除过期的键,默认情况下设置为每秒 10 次,通过配置文件中的 hz 参数控制。
Redis 内存溢出有哪几种数据淘汰策略?
当触发 Redis 内存的 maxmemory 最大设置之后会触发内存溢出数据淘汰策略,共支持 6 种策略,默认值为 maxmemory-policy noeviction,6 种策略如下所示:
- noeviction:默认淘汰机制,不会删除任何数据,会拒绝所有的写入命令,读取是正常的
- volatile-lru:使用 LRU 算法删除设置了 Expire 属性且最少使用的键,直到新添加的数据能够有空间可以存放,否则退回 noeviction 规则
- allkeys-lru:使用 LRU 算法删除键,不论有没有设置 Expire 属性,直到新添加数据能够有空间存放
- volatile-random:随机删除设置了 Expire 属性的键,直到腾出空间
- allkeys-random:随机删除所有键,直到腾出空间
- volatile-ttl:根据键值对象的 ttl 属性优先回收存活时间短的键,否则退回 noeviction 规则
看完两件小事
如果你觉得这篇文章对你挺有启发,我想请你帮我两个小忙:
- 把这篇文章分享给你的朋友 / 交流群,让更多的人看到,一起进步,一起成长!
- 关注公众号 「IT平头哥联盟」,公众号后台回复「资源」 免费领取我精心整理的前端进阶资源教程
